
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- autogluon
- timechat
- 코딩테스트
- LeNet-5
- Kaggle
- Github
- secure-file-priv
- jmeter
- error
- Python
- memory bank
- sliding video q-former
- multimodal machine learning
- transference
- q-former
- CNN
- Anaconda
- timestamp-aware frame encoder
- Linux
- 백준
- leetcode
- 용어
- ma-lmm
- quantification
- MySQL
- tensorflow
- Server
- Artificial Intelligence
- hackerrank
- long video understanding
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- autogluon
- timechat
- 코딩테스트
- LeNet-5
- Kaggle
- Github
- secure-file-priv
- jmeter
- error
- Python
- memory bank
- sliding video q-former
- multimodal machine learning
- transference
- q-former
- CNN
- Anaconda
- timestamp-aware frame encoder
- Linux
- 백준
- leetcode
- 용어
- ma-lmm
- quantification
- MySQL
- tensorflow
- Server
- Artificial Intelligence
- hackerrank
- long video understanding
- Today
- Total
Juni_DEV
인공지능 용어 정리 (2) 본문
지도 학습 (= Supervised Learning) :
목표값(정답)이 있는 훈련 데이터들을 이용하여
임의의 데이터로부터 예측하고자 하는 값을 올바르게 추측해내는 함수를 학습하는 방법
훈련 데이터로부터 하나의 함수를 유추해내기 위한 기계학습의 한 방법
=> 주어진 데이터에 대해 예측하고자 하는 값을 올바르게 추측해내는 것
훈련 데이터를 기반으로 유추된 함수 중 연속적인 값을 출력하는 것을 회귀분석(=Regression)이라 하고
주어진 입력 값이 어떤 종류의 값인지 표식 하는 것을 분류라고 함
회귀분석 (=Regression) :
관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해내는 분석 방법
시간에 따라 변화하는 데이터나 어떤 영향, 가설적 실험, 인과관계의 모델링 등의 통계적 예측에 사용됨
-
선형 회귀 (=Linear Regression) : 종속변수 y와 한 개 이상의 독립변수 x와의 선형 상관관계를 모델링하는 회귀분석 기법
-
로지스틱 회귀 (=Logistic Regression) : 독립변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용되는 통계 기법
종속변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉨
=> 일종의 분류 기법
흔히 종속변수가 이항형 문제를 지칭할 때 사용 (Binary : 2항 / Multinomial… : 2항 이상 )
비지도 학습(= UnSupervised Learning) :
목표값이 없는 데이터들을 이용하여 데이터들의 분포 또는 군집에 대한 정보를 학습하는 방법
기계 학습의 일종으로 데이터가 어떻게 구성되었는지를 알아내는 문제의 범주에 속함
입력 값에 대한 목표치가 주어지지 않는다.
통계의 밀도 추정과 깊은 연관이 있음, 데이터의 주요 특징을 요약하고 설명할 수 있다. (ex. 클러스터링, 독립 성분 분석)
클러스터링 분석 (=Cluster Analysis) :
클러스터 (=Cluster) : 비슷한 특성을 가진 데이터들의 집단
주어진 데이터들의 특성을 고려해 데이터 집단(클러스터)을 정의하고
데이터 집단의 대표할 수 있는 대표점을 찾는 것으로 데이터 마이닝의 한 방법
준 지도 학습(= Semi-Supervised Learning) :
목표값이 있는 데이터들과 목표값이 없는 데이터들을 모두 이용하여
임의의 데이터에 대한 목표값을 예측하는 함수를 학습하는 방법
점진적 학습 ( Incremental Learning ) :
추가되는 데이터로부터 새로운 정보를 학습하여 이미 습득된 기존의 지식을 갱신하는 학습법
적합도 : 관찰 결과가 이론에 잘 맞는 정도, 실험 결과와 이론 기대치 간의 적합 정도
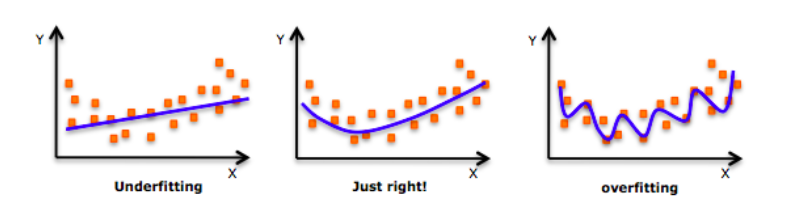
Underfitting (Overfitting 반대 개념) :
-
데이터에 모델을 너무 대충 맞춰서 error가 너무 많이 발생하는 현상
Overfitting (=과 적합, 과잉 적합) :
-
통계모델이 과도하게 학습 데이터 맞춤형으로 만들어져 다른 상황에 일반화되지 못하는 것
-
모델이 트레이닝 셋에 너무 최적화되어 있어서, 실제 모델(=테스트 셋)과 맞지 않게 되는 것
-
통계모델에 매개변수가 너무 많은 경우, 학습 데이터수에 비해 모델이 복잡하고 예측력이 떨어짐
-
Weight값이 너무 큰 경우, 모델이 복잡해짐
-
방지 기법
-
매개변수(Parameter) 개수 줄이기
-
Regularization
Parameter (= 매개변수)
-
Hyper Parameter : 모델 학습 전에 미리 지정해야 하는 학습 알고리즘이 자체적으로 가지고 있는 파라미터
-
Model Parameter : 학습을 통해 만들어진 모델의 파라미터
K-NN (=K-Nearest Neighbor) : 최근접 이웃 알고리즘
SVM (=Support Vector Machine) :
기계학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도 학습 모델이며, 주로 분류와 회귀분석을 위해 사용한다.
두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때, SVM 알고리즘은 주어진 데이터 집합을 바탕으로 하여 새로운 데이터가 어느 카테고리에 속할지 판단하는 비확률적 이진 선형 분류 모델을 만든다.
NBC (=Naive Bayes Classifier) :
베이즈(Bayes) 정리를 활용한 단순(naive) 분류기, 입력값이 서로 독립이라 가정하기 때문에 Naive 하다고 한다.
역전파 (=오차 역전파, Backpropagation, 오류 역전파법) : 다층 퍼셉트론 학습에 사용되는 통계적 기법
-
다층 퍼셉트론 : 기계학습에 사용되는 학습 구조
-
다층 퍼셉트론의 형태는 입력층 - 은닉층 - 은닉층 -…- 출력층으로 구성되며, 각 층은 서로 교차되는 weight 값으로 연결되어 있다.
-
오차 역전법은 동일 입력층에 대해 원하는 값이 출력되도록 error에 따라 개개의 weight을 조정하는 방법으로 사용되며, 속도는 느리지만, 안정적인 결과를 얻을 수 있는 장점이 있어 기계학습에 널리 사용되고 있다.

퍼셉트론 (=Perceptron) : 인공신경망의 한 종류, 시각과 뇌의 기능을 모델화한 학습 기계
동작 방식 => 각 노드의 가중치와 입력치를 모두 합한 값이 활성 함수에 의해 판단되는데, 그 값이 임계치(보통 0) 보다크면 뉴런이 활성화되고 결과값으로 1을 출력하고 활성화되지 않으면 결과값으로 -1을 출력한다.
MLP (=Multi-Layer Perceptron, Multi-layer NN, MLNN) : 기존 다계층 신경망

DNN (=Deap Neural Network, 심층 신경망) :
입력층과 출력층 사이에 여러 개는 은닉층(=hidden layer)들로 이뤄진 인공신경망(=Artificial Neural Networ, ANN)
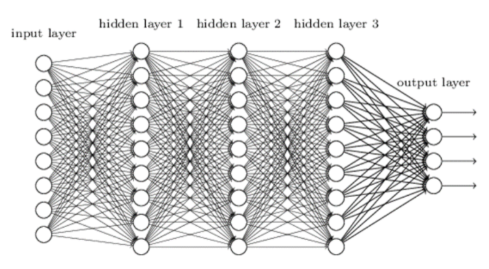
Vanshing Gradient (=가중치 소멸 문제, 기울기 값이 사라지는 문제) :
x=0에서 멀어질수록 기울기가 0으로 수렴하기 때문에, 활성화 값이 0 또는 1에 치우쳐 분포하게 되면 기울기가 점점 작아지다가 사라지는 것
활성화 함수로 사용된 sigmoid 함수가 input을 작은 output range(0~1)에 비선형적으로 욱여넣기 때문에 발생하는 문제
=> 이런 성질을 갖지 않는 비선형 함수를 활성화 함수로 선택하면 해결할 수 있다. (ReLU 함수)
Exploding Gradient (=가중치 폭발 문제) : gradient가 폭발적으로 발산함
Activation Function (= 활성 함수) :
인공신경망에서 입력받은 데이터를 다음 층으로 출력할지를 결정하는 역할
인공 신경망 모델에서 뉴런은 층으로 구성되고 층에는 여러 개의 노드로 구성되어 있음
=> 하나의 노드는 1개 이상의 노드와 연결되어있고 데이터 입력을 받게 되는데 연결 강도의 가중치의 합을 구하게 되고 활성화 함수를 통해 가중치의 값의 크기에 따라 출력하게 됨
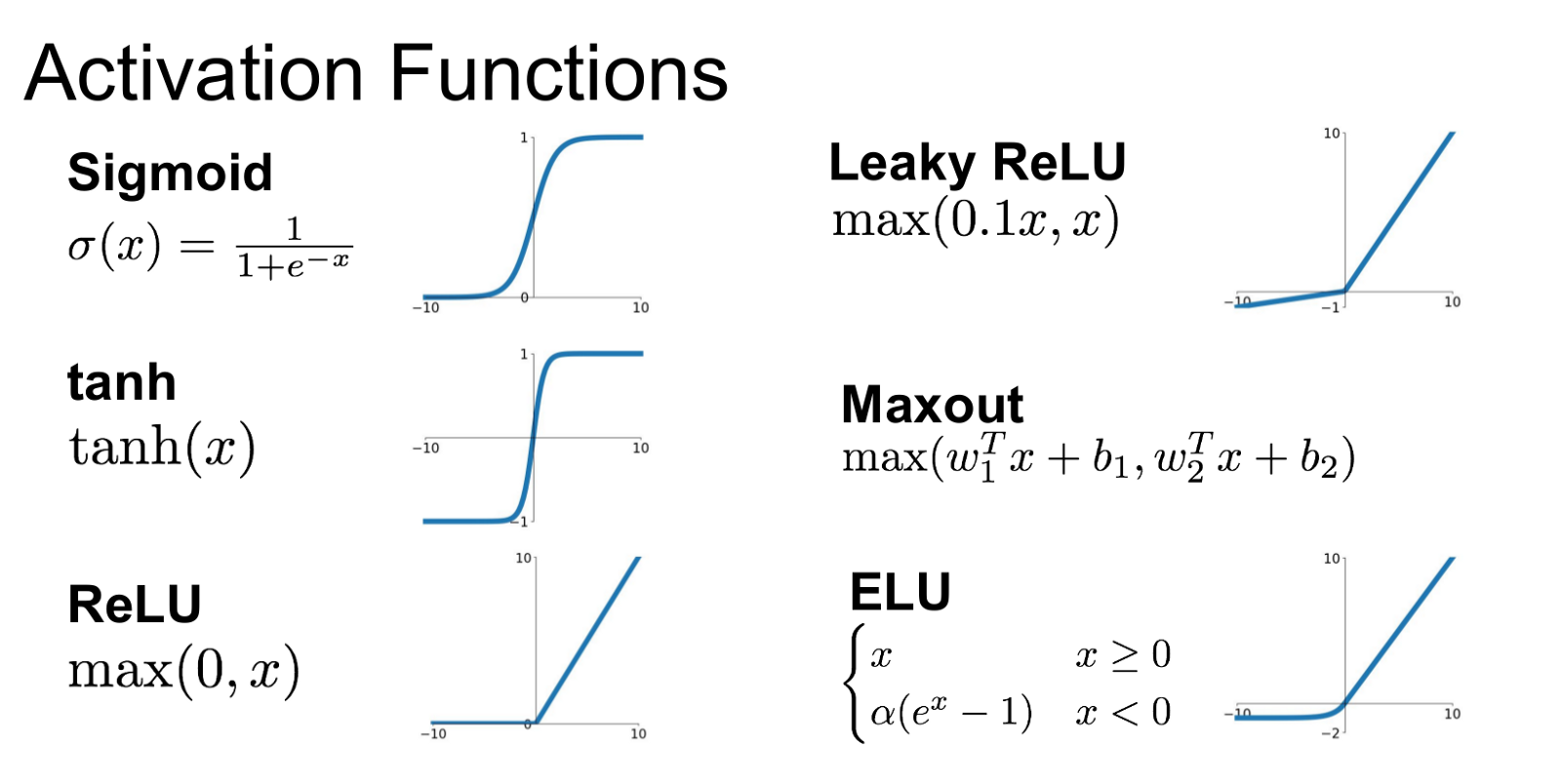
ReLU (=Rectified linear unit) :
DNN에서 활성화 함수로 사용됨
f(x) = max(0, x)로 정의되며, tanh와 같은 활성화 함수들에 비해 활성화 결과가 쉽게 0으로 설정되기 때문에 희소성이 높고 vanishing gradient 문제로 인한 피해가 적다.
CNN에서 가장 일반적으로 사용되는 활성화 함수이며, Leaky ReLU, Parametric ReLU 등의 여러 변형이 있음
선형 함수 : 예측 가능, 직선의 형태인 함수
비선형 함수 : 예측 불가능, 직선의 형태가 아닌 함수
MNIST : 필기 숫자 인식 문제 (이미지 인식)
Epoch: 학습용 데이터 전체를 한 번 학습시켰을 때 1 epoch라고 함
=> one epoch : one forward pass and onebackward pass of all the training examples
Batch size * iteration = 전체 데이터수
Batch Size : 한 번에 몇 개씩 데이터를 학습시킬지를 의미 (일괄 처리)
=> Batch size : the number of training examples int one forward/backward pass.
The higher the batch size, the more memory space you'll need.
Iteration : 몇 개의 batch를 사용할 건지를 의미
=> iterations : number of passes, each pass using [batch size] number of examples.
To be clear, one pass = one forward pass+one backward pass.
(we do not count the forward pass and backward pass as two different passes)
Epoch, Batch, Iteration 설명
[ 어차피 학습과정이니 시험 보는 것에 비유해봤습니다. 모의고사 1부에 100문항이 있다고 가정합니다.
epoch는 같은 모의고사를 몇 번 풀 것이냐입니다.
epoch가 10이면 같은 모의 고사지를 10번 푸는 것과 동일합니다.
처음 epoch를 접할 때는 동일한 데이터셋을 여러 번 사용하는 것이 도움이 돼?라고 생각했는데, 같은 모의 고사지를 여러 번 푼다고 생각해보니, 점점 학습이 될 것 같더군요.
batch size는 몇 문항을 보고 답을 맞혀볼까입니다.
실전처럼 하는 사람은 전 문항을 다 풀고 난 다음 답을 맞혀서 오답정리를 하는 사람도 있고 성격이 급한 사람은 한 문제 풀고 답 맞추는 사람도 있겠죠.
처음엔 이것도 학습에 무슨 영향을 미칠까 의아해했는데, 같은 모의 고사지에 비슷한 문제가 있을 경우 다 풀어보고 맞춘 사람은 한 문제 틀리면 다른 유사문제들도 다 틀리겠지만, 한 문항 보고 오답 정리한 사람은 첫 문제를 틀리더라도 다른 남은 문제들은 맞힐 확률이 높아지겠죠.
그밖에 train, validation, test 셋을 왜 나누어야 하는 지도 모의고사, 실전 모의고사, 실제 수능 등으로 생각해보니 당연히 그렇게 해야겠구나 생각이 들더군요. ]
FFNN (=Feed-Forward Neural Network) :
인풋 x를 받아서 이것의 y = Wx+b를 계산하고, 여기에 activation function (=활성 함수, 예를 들면 sigmoid, tanh, ReLU)를 적용한다. (a = σ(y) )
이 과정을 하나의 layer로 볼 수 있는데, 이것들을 여러 개 쌓아 올린 후 마지막에 output layer를 쌓아 올린 것이 바로 Multilayer Perceptron (MLP)가 되는 것이다.
output layer의 값은 0~1 사이의 값을 가지게 하는 게 보통으로, 이를 위해 주로 softmax function을 activation function으로 이용함.
Topology (= 토폴로지, 망구성 방식)
Cost function(=비용 함수, loss function, 손실 함수) :
모델의 정확도를 측정할 때 활용되며, 비용 함수란 예측 값과 실제 값 차이의 평균을 의미한다.
Saturation (=포화) :
sigmoid, tanh 함수는 어떠한 값이 들어와도 -1~1, 혹은 0~1 사이의 값을 배출함
=> 그렇다면 큰 값이 들어왔을 때도, 저 사이의 값을 내놓아 saturation(포화)됨
하지만 ReLU는 max(0, x)이므로 어떠한 값이 들어와도 제한이 없음
값이 크면 클수록 더 큰 gradient를 가지게 된다.
ICA (=Independent Component Analysis, 독립 성분 분석) :
다변량의 신호를 통계적으로 독립적인 하부 성분으로 분리하는 계산 방법
PCA (=Principal Component Analysis, 주 성분 분석) :
고차원의 데이터를 저차원의 데이터로 환원시키는 기법
첫째 주성분이 가장 큰 분산을 가지고, 이후의 주성분들은 이전의 주성분들과 직교한다는 제약 아래에 가장 큰 분산을 갖고 있다는 식으로 정의되어 있다.
-
분산 : 확률변수가 기댓값으로부터 얼마나 떨어진 곳에 분포하는지를 가늠하는 숫자

'Artificial Intelligence' 카테고리의 다른 글
| Anaconda 환경 세팅 및 CUDA, cuDNN 설치 (Window, AMD Ryzen GPU) (0) | 2022.05.26 |
|---|---|
| Cross validation 종류 (0) | 2019.06.18 |
| 인공지능 용어 정리 (3) (0) | 2019.06.11 |
| 이미지 인식 용어 정리 (2) | 2019.06.08 |
| 인공지능 용어 정리 (1) (0) | 2019.06.06 |



