
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Linux
- Reinforcement Learning
- deeprl
- leetcode
- transference
- 코딩테스트
- CS285
- long video understanding
- LeNet-5
- Github
- 용어
- memory bank
- error
- Server
- Anaconda
- hackerrank
- Artificial Intelligence
- tensorflow
- CNN
- autogluon
- 백준
- Kaggle
- quantification
- sliding video q-former
- Python
- multimodal machine learning
- ma-lmm
- jmeter
- MySQL
- vision-language-action
Archives
- Today
- Total
반응형
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- Linux
- Reinforcement Learning
- deeprl
- leetcode
- transference
- 코딩테스트
- CS285
- long video understanding
- LeNet-5
- Github
- 용어
- memory bank
- error
- Server
- Anaconda
- hackerrank
- Artificial Intelligence
- tensorflow
- CNN
- autogluon
- 백준
- Kaggle
- quantification
- sliding video q-former
- Python
- multimodal machine learning
- ma-lmm
- jmeter
- MySQL
- vision-language-action
Archives
- Today
- Total
Juni_DEV
[CS285: Deep RL 2023] Lecture 2, Imitation Learning 본문
Robotics/Reinforcement Learning
[CS285: Deep RL 2023] Lecture 2, Imitation Learning
junni :p 2025. 7. 21. 17:25반응형
Terminology & notation

Markov property (Very Very Important!!!)
- If you know the state S2 and you need to figure out the state S3 then S1 doesn’t give you any additional information that means that S3 is conditionally independent S1 given S2.
- If you know the state now, then the state in the past does not matter to you because you know everything about the state of the world.
- 현재는 모든 과거를 온전히 표현한다 → 미래의 state를 예측할때 과거를 기억하지 않고 현재만을 고려함
Imitation Learning
The moral of the story, and a list of ideas
- Imitation learning via behavioral cloning is not guaranteed to work
- This is different from supervised learning
- The reason: i.i.d. assumption does not hold!
- We can formalize why this is and do a bit of theory
- We can address the problem in a few ways:
- Be smart about how we collect (and augment) our data
- Use very powerful models that make very few mistakes
- Use multi-task learning
- Change the algorithm (DAgger)
Why does behavioral cloning fail?
The distributional shift problem
- That the distribution under which the policy is tested is shifted from the distribution under which it’s trained .
Where are we…
- Imitation learning via behavioral cloning is not guaranteed to work
- This is different from supervised learning
- The reason: i.i.d. assumption does not hold!
- We can formalize why this is and do a bit of theory
- We can address the problem in a few ways:
- Be smart about how we collect (and augment) our data
- Use very powerful models that make very few mistakes
- Use multi-task learning
- Change the algorithm (DAgger)
What makes behavioral cloning easy and what makes it hard?
- Intentionally add mistakes and corrections
- The mistakes hurt, but the correctins help, often more than the mistakes hurt
- Use data augmentation
- Add some “fake” data that illustrates corrections (e.g., side-facing cameras)
Why might we fail to fit the expert?
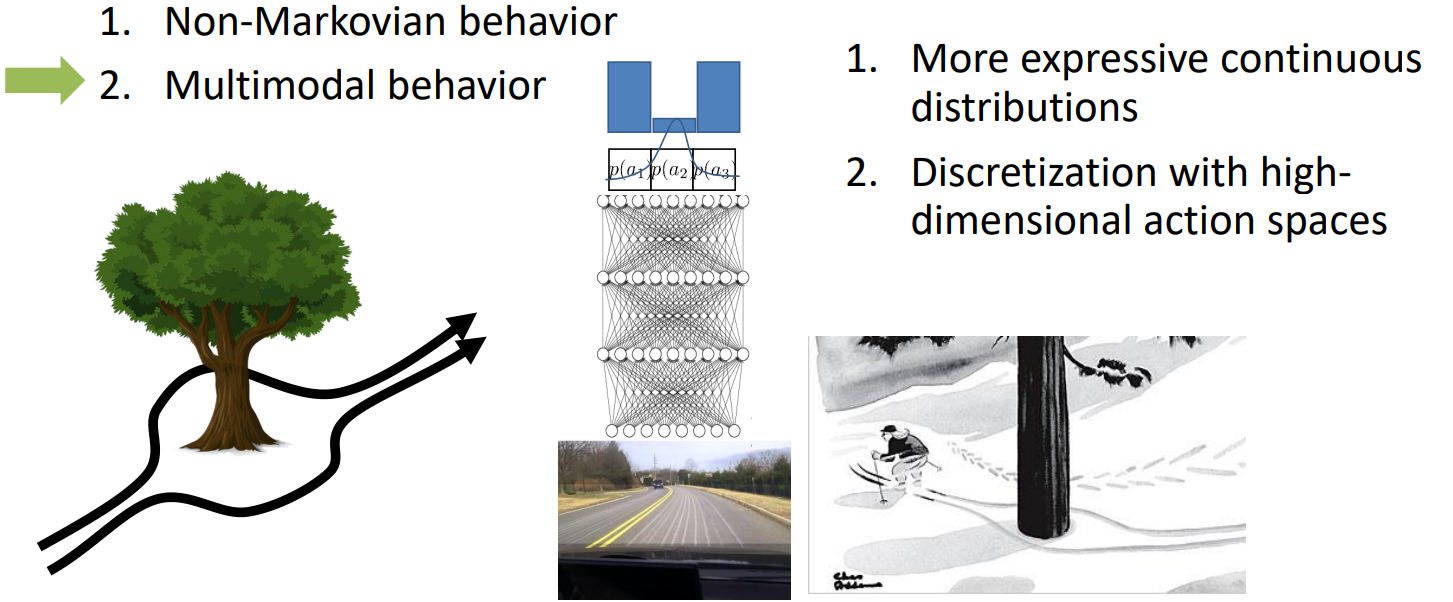
1. Non-Markovian behavior
- that the expert doesn’t necessarily choose the action based only on the current state

2. Multimodal behavior
- that the expert takes actions randomly and their distribution of reactions is very complex and might have multiple modes
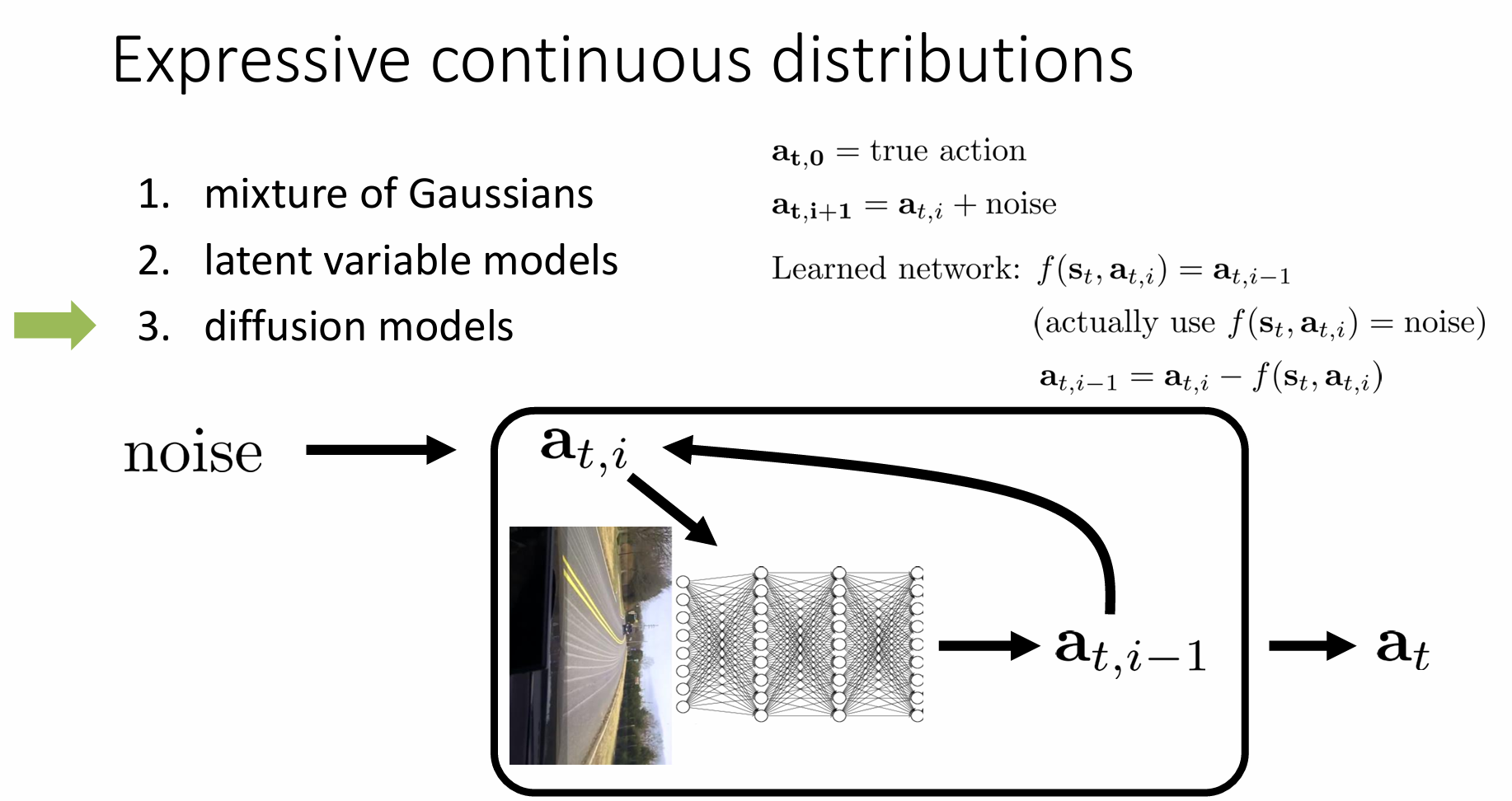
Expressive continuous distributions
Quite a few options, many ways to make things work:
- mixture of Gaussians
- set of means covariances and weights
- modern auto devtools like pytorch → pretty easy to implement
- problem of the mixture of Gaussians is that you choose a number of mixture elements and that’s how many you have
- latent variable models
- provice us a way to represent a much broader class of distributions in fact you can actually show that latent variable models can represent any distribution as long as the neural network is big enough
- random seed ⇒ random numbers aren’t actually correlated with anything in the input or output ⇒ newral net will ignore those numbers
- trick in training latent variable models is to make those numbers useful during training
- The most widely used type of model of this sort is the (conditional) variational autoencoder
- Diffusion models

Does learning many tasks become easier?
Use multi-task learning
Goal-conditioned Behavioral Cloning
- can use them as online self-improvement method very similar in spirit to RL
- Start with a random policy
- Collect data with random goals
- Treat this data as “demonstrations” for the goals that were reached
- Use this to improve the policy
- Repeat
- The idea is initially the policy does mostly random things, but then it learns about the actions that led to the states that actually reached and then it can be more deliberate on the next iterations.
- So the mehod simply applies this goal relabeling immitation learning approach iteratively running relabeling imitation, then more data collection, then more relabeling and then more imitation.
Hindsight Experience Replay
- Similar principle but with reinforcement learning
- This will make more sense later once we cover off-policy value-based RL algorithms
- Worth mentioning because this idea has been used widely outside of imitation (and was arguably first propsed there)
Change the algorithm (DAgger)

3. Ask human to label with actions ⇒ sometimes not very natural to ask a human to examine images
Imitaiton learning: what’s the problem?
- Humans need to provide data, which is typically finite
- Deep learning works best when data is plentiful
https://rail.eecs.berkeley.edu/deeprlcourse/
https://rail.eecs.berkeley.edu/deeprlcourse/deeprlcourse/static/slides/lec-2.pdf
https://www.youtube.com/playlist?list=PL_iWQOsE6TfVYGEGiAOMaOzzv41Jfm_Ps
CS 285: Deep RL, 2023
Playlist for videos for the UC Berkeley CS 285: Deep Reinforcement Learning course, fall 2023.
www.youtube.com
반응형
'Robotics > Reinforcement Learning' 카테고리의 다른 글
| [CS285: Deep RL 2023] Lecture 3, PyTorch and Neural Nets (0) | 2025.07.23 |
|---|---|
| [CS285: Deep RL 2023] Lecture 1, Introduction (2) | 2025.07.21 |
'Robotics/Reinforcement Learning' Related Articles
more

Comments