
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- jmeter
- long video understanding
- 용어
- Github
- LeNet-5
- Python
- multimodal machine learning
- Anaconda
- 코딩테스트
- timechat
- ma-lmm
- secure-file-priv
- autogluon
- sliding video q-former
- transference
- tensorflow
- MySQL
- leetcode
- hackerrank
- Artificial Intelligence
- CNN
- Kaggle
- q-former
- quantification
- 백준
- Linux
- timestamp-aware frame encoder
- Server
- memory bank
- error
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- jmeter
- long video understanding
- 용어
- Github
- LeNet-5
- Python
- multimodal machine learning
- Anaconda
- 코딩테스트
- timechat
- ma-lmm
- secure-file-priv
- autogluon
- sliding video q-former
- transference
- tensorflow
- MySQL
- leetcode
- hackerrank
- Artificial Intelligence
- CNN
- Kaggle
- q-former
- quantification
- 백준
- Linux
- timestamp-aware frame encoder
- Server
- memory bank
- error
- Today
- Total
목록2024/10 (2)
Juni_DEV
멀티모달 러닝은 다양한 형태의 데이터(예: 텍스트, 이미지, 음성 등)를 통합하여 컴퓨터가 이를 이해하고, 추론하고, 학습할 수 있도록 돕는 인공지능 기술입니다. 멀티모달 러닝의 목표는 다양한 데이터를 연계하여 통합적으로 처리할 수 있는 지능형 컴퓨터 에이전트를 설계하는 것입니다. 여기에서는 멀티모달 러닝의 핵심 원칙과 대표적인 기술적 과제들을 정리해보겠습니다.멀티모달 러닝의 핵심 원칙멀티모달 러닝의 기본 원칙은 크게 다음 세 가지로 요약할 수 있습니다.모달리티의 이질성: 서로 다른 데이터 유형(텍스트, 이미지, 소리 등)은 고유한 특성과 구조를 가지며, 이를 잘 반영해야만 최적의 결과를 얻을 수 있습니다.모달리티 간의 연결: 각 모달리티 간의 연관성을 파악하고 연결함으로써 서로 보완적인 정보를 통합합니..
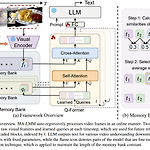 [논문리뷰] MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
[논문리뷰] MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
https://arxiv.org/abs/2404.05726이 논문에서는 MA-LMM(Memory-Augmented Large Multimodal Model)을 제안하여 Long-Term Video Understanding를 위한 새로운 접근법을 제시하고 있습니다. 기존의 LLM 기반 모델들이 짧은 비디오 이해에만 적합한 반면, MA-LMM은 장기 비디오 시퀀스를 온라인으로 처리하고, 이전 비디오 정보를 메모리 뱅크에 저장하여 효율적으로 분석합니다. 이로 인해 LLM의 컨텍스트 길이 제한이나 GPU 메모리 한계를 초과하지 않고도 긴 비디오를 다룰 수 있습니다.MA-LMM ArchitectureMA-LMM의 기본 구조는 크게 세 부분으로 나눌 수 있습니다.Visual Encoder: 입력된 비디오의 각 프레..