
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- hackerrank
- error
- Python
- ma-lmm
- timestamp-aware frame encoder
- jmeter
- Server
- memory bank
- 용어
- autogluon
- timechat
- quantification
- tensorflow
- CNN
- LeNet-5
- multimodal machine learning
- long video understanding
- 코딩테스트
- Github
- sliding video q-former
- 백준
- q-former
- Linux
- Anaconda
- MySQL
- Kaggle
- transference
- secure-file-priv
- Artificial Intelligence
- leetcode
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- hackerrank
- error
- Python
- ma-lmm
- timestamp-aware frame encoder
- jmeter
- Server
- memory bank
- 용어
- autogluon
- timechat
- quantification
- tensorflow
- CNN
- LeNet-5
- multimodal machine learning
- long video understanding
- 코딩테스트
- Github
- sliding video q-former
- 백준
- q-former
- Linux
- Anaconda
- MySQL
- Kaggle
- transference
- secure-file-priv
- Artificial Intelligence
- leetcode
- Today
- Total
목록Artificial Intelligence (18)
Juni_DEV
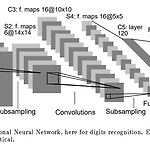 [CNN, Pytorch] LeNet-5 구현하기
[CNN, Pytorch] LeNet-5 구현하기
논문에 나와있는 Lenet-5 구조Input Layer : 32x32C1 (Convolution) : 28x28x6S2 (Subsampling) : 14x14x6C3 (Convolution) : 10x10x16S4 (Subsampling) : 5x5x16C5 (Fully connection) : Layer 120F6 (Fully Connection) : Layer 84Output (Gaussian connections) : 10구조까지는 파악하겠는데 도무지 어떻게 시작해야 될지 모르겠다.다른 분이 작성한 코드를 보고 Colab 이용해서 공부하는 걸로 일단 노선 변경구현 완료한 Pytorch LeNet-5 Codehttps://github.com/juni5184/Paper_review/blob/main/(..
딥러닝 모델 프로세스 라이브러리 임포트 데이터 가져오기 데이터 분석 데이터 전처리 Train, Test 데이터셋 분할 데이터 정규화 딥러닝 모델 구현 모델 성능평가 1. 라이브러리 임포트 import numpy as np import pandas as pd import matplotlib.pyplot as plt 2. 데이터 가져오기 df = pd.read_csv('data.csv') # data.csv 파일을 읽어와서 df 변수에 저장 3. 데이터 분석 df.info() # index, 컬럼명, Non-Null Count, Dtype df.head() # 앞에서 5개 컬럼 보여줌 df.tail() # 뒤에서 5개 컬럼 보여줌 4. 데이터 전처리 모든 데이터 값은 숫자형이어야 함, Object 타입 ->..
머신러닝 모델 프로세스 라이브러리 임포트 데이터 가져오기 데이터 분석 데이터 전처리 Train, Test 데이터셋 분할 데이터 정규화 모델 구현 단일 분류 예측 모델 : LogisticRegression, KNN, Decision Tree 앙상블 모델 : RandomForest, XGBoost, LGBM 모델 성능 평가 1. 라이브러리 임포트 import numpy as np import pandas as pd import matplotlib.pyplot as plt 2. 데이터 가져오기 df = pd.read_csv('data.csv') # data.csv 파일을 읽어와서 df 변수에 저장 3. 데이터 분석 df.info() # index, 컬럼명, Non-Null Count, Dtype df.head..
df.info() : 데이터프레임 형태, 타입, null 여부를 한 번에 보기 df.index : 데이터프레임의 인덱스 df.columns : 데이터프레임의 컬럼명 df.values : 데이터프레임의 값 df.isnull() : 데이터프레임 모든 컬럼에 대한 null 한 번에 확인 df.isnull().sum() : 컬럼 - 개수로 표시 df.describe() : 데이터프레임에서 숫자형에 대한 통계정보 보기 df['특정컬럼'] : 특정 컬럼의 값만 확인, 검색 (df ['컬럼'] == '') | (df['컬럼'] == ' ') : 해당 컬럼에 공백이 있는지 확인 df['컬럼'].replace(' ', 0, inplace = True) : 컬럼의 공백을 0으로 변경 df['컬럼'] = df['컬럼'].a..
 Anaconda 환경 세팅 및 CUDA, cuDNN 설치 (Window, AMD Ryzen GPU)
Anaconda 환경 세팅 및 CUDA, cuDNN 설치 (Window, AMD Ryzen GPU)
1. Anaconda 설치아나콘다 환경을 사용하면 가상환경을 독립적으로 만들어 관리하기 쉽다. Anaconda | Anaconda DistributionAnaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine.www.anaconda.comAnaconda setting 참고 글 아나콘다 설치, 환경변수 설정, 개발환경 설정, anaconda 설치설치 전에 절대 주의사항... 충돌 이슈.... 파이썬 지우세요!!!!!!!!!!!!!!!! 파이썬 지우세요!!!!!!!!!!!!!!!! 파이썬 지우세요!!!!!!!!!!!!!!!! 파이썬 지우..
 Cross validation 종류
Cross validation 종류
Cross Validation 종류 1. K-fold Cross-validation 데이터셋을 K개의 sub-set으로 분리하는 방법 분리된 K개의 sub-set중 하나만 제외한 K-1개의 sub-sets를 training set으로 이용하여 K개의 모델 추정 일반적으로 K=5, K=10 사용 (-> 논문참고) K가 적어질수록 모델의 평가는 편중될 수 밖에 없음 K가 높을수록 평가의 bias(편중된 정도)는 낮아지지만, 결과의 분산이 높을 수 있음 2. Hold-out Validation Train/Test Split K를 1로 설정하여 하나의 학습/테스트 Split을 만들어 모델을 평가 3. LOOCV (Leave-one-out Cross-validation) fold 하나에 샘플 하나만 들어있는 K겹..
 인공지능 용어 정리 (3)
인공지능 용어 정리 (3)
CUDA (= Computer Unified Device Architecture ) : NVIDIA 에서 제공하는 GPU의 병렬 특성을 이용한 API 레이어 CUDNN (= CUDA Deep Neural Network ) : CUDNN 라이브러리는 딥러닝 알고리즘을 위한 기본 요소를 제공한다. NVIDIA 에서 제공하는 패키지이므로 하드웨어에 최적화되어 있으며 더 빠르게 실행될 수 있다. 이 패키지는 딥러닝을 위한 몇 가지 기본 루틴을 제공한다. Python -> 파이썬을 왜 사용하는가 모든 데이터 사이언스 애플리케이션을 위한 사실상의 표준이라고 할 수 있으며, 라이브러리 중 가장 큰 커뮤니티와 지원 생태계를 갖고 있다. Python Package Numpy : 고도로 최적화된 수학 연산 패키지. 강력한..
 인공지능 용어 정리 (2)
인공지능 용어 정리 (2)
지도 학습 (= Supervised Learning) : 목표값(정답)이 있는 훈련 데이터들을 이용하여 임의의 데이터로부터 예측하고자 하는 값을 올바르게 추측해내는 함수를 학습하는 방법 훈련 데이터로부터 하나의 함수를 유추해내기 위한 기계학습의 한 방법 => 주어진 데이터에 대해 예측하고자 하는 값을 올바르게 추측해내는 것 훈련 데이터를 기반으로 유추된 함수 중 연속적인 값을 출력하는 것을 회귀분석(=Regression)이라 하고 주어진 입력 값이 어떤 종류의 값인지 표식 하는 것을 분류라고 함 회귀분석 (=Regression) : 관찰된 연속형 변수들에 대해 두 변수 사이의 모형을 구한 뒤 적합도를 측정해내는 분석 방법 시간에 따라 변화하는 데이터나 어떤 영향, 가설적 실험, 인과관계의 모델링 등의 통..