
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Reinforcement Learning
- 코딩테스트
- tensorflow
- LeNet-5
- vision-language-action
- MySQL
- ma-lmm
- Github
- CNN
- deeprl
- Linux
- CS285
- hackerrank
- Python
- 백준
- Anaconda
- error
- jmeter
- quantification
- long video understanding
- 용어
- memory bank
- Server
- Kaggle
- autogluon
- transference
- multimodal machine learning
- Artificial Intelligence
- sliding video q-former
- leetcode
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Reinforcement Learning
- 코딩테스트
- tensorflow
- LeNet-5
- vision-language-action
- MySQL
- ma-lmm
- Github
- CNN
- deeprl
- Linux
- CS285
- hackerrank
- Python
- 백준
- Anaconda
- error
- jmeter
- quantification
- long video understanding
- 용어
- memory bank
- Server
- Kaggle
- autogluon
- transference
- multimodal machine learning
- Artificial Intelligence
- sliding video q-former
- leetcode
- Today
- Total
Juni_DEV
[CNN, Pytorch] LeNet-5 구현하기 본문

논문에 나와있는 Lenet-5 구조
- Input Layer : 32x32
- C1 (Convolution) : 28x28x6
- S2 (Subsampling) : 14x14x6
- C3 (Convolution) : 10x10x16
- S4 (Subsampling) : 5x5x16
- C5 (Fully connection) : Layer 120
- F6 (Fully Connection) : Layer 84
- Output (Gaussian connections) : 10
구조까지는 파악하겠는데 도무지 어떻게 시작해야 될지 모르겠다.
다른 분이 작성한 코드를 보고 Colab 이용해서 공부하는 걸로 일단 노선 변경
구현 완료한 Pytorch LeNet-5 Code
https://github.com/juni5184/Paper_review/blob/main/(pytorch)lenet-5.ipynb
GitHub - juni5184/Paper_review
Contribute to juni5184/Paper_review development by creating an account on GitHub.
github.com
(1) 구글 Mount 하기
from google.colab import drive
drive.mount('LeNet-5')여기서 마운트(mount)는
리눅스에서 쓰이던 개념으로 물리적인 장치를 특정한 위치(대개는 디렉터리)에 연결해주는 과정을 뜻한다.
구글 드라이브에 LeNet-5 폴더를 연결하는 건가?
- 실행했더니 디렉터리에 LeNet-5라는 폴더가 생기고 그 안에 내 Google Drive가 'MyDrive'라는 이름으로 포함되어 있었다.
(2) 필요한 라이브러리 import
import numpy as np
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'torch를 사용해서 구현할 예정
(3) Parameters 설정하기
RANDOM_SEED = 42
LEARNING_RATE = 0.001
BATCH_SIZE = 32
N_EPOCHS = 15
IMG_SIZE = 32
N_CLASSES = 10예전에 궁금해서 코드의 RANDOM_SEED에는 왜 "42"가 자꾸 쓰이는 건지 찾아본 적이 있다.
찾아본 결과 딱히 기술적 의미가 있는 건 아니었고,
Douglas Adams의 "은하수를 여행하는 히치하이커를 위한 안내서"라는 책의 슈퍼컴퓨터 Deep Thought가
750년 동안 계산한 삶, 우주 그리고 모든 것에 대한 궁극적인 해답의 결과가 "42"라고 한다.
여기서 유래되어 문화로 자리 잡은 듯
(4-1) 정확도를 구하는 function 정의
def get_accuracy(model, data_loader, device):
'''
전체 data_loader에 대한 예측의 정확도를 계산하는 함수
'''
correct_pred = 0
n = 0
with torch.no_grad():
model.eval()
for X, y_true in data_loader:
X = X.to(device)
y_true = y_true.to(device)
_, y_prob = model(X)
_, predicted_labels = torch.max(y_prob, 1)
n += y_true.size(0)
correct_pred += (predicted_labels == y_true).sum()
return correct_pred.float() / ntorch.no_grad() : autograd engine(gradient를 계산해주는 context)을 비활성화시켜 필요한 메모리를 줄여주고 연산속도를 증가시키는 역할을 한다.
model.eval() : 학습할 때만 필요했던 Dropout, Batchnorm 등의 기능을 비활성화해줘서 추론할 때의 모드로 작동하도록 조정해주는 역할을 한다. (메모리와는 관련 X)
(4-2) 손실을 시각화하는 function 정의
def plot_losses(train_losses, valid_losses):
'''
training과 validation loss를 시각화하는 함수
'''
# plot style을 seaborn으로 설정
plt.style.use('seaborn')
train_losses = np.array(train_losses)
valid_losses = np.array(valid_losses)
fig, ax = plt.subplots(figsize = (8, 4.5))
ax.plot(train_losses, color='blue', label='Training loss')
ax.plot(valid_losses, color='red', label='Validation loss')
ax.set(title="Loss over epochs",
xlabel='Epoch',
ylabel='Loss')
ax.legend()
fig.show()
# plot style을 기본값으로 설정
plt.style.use('default')matplotlib 이용해서 train, validation 그래프 그려줄 예정, seaborn style
(5) training data에 사용되는 helper 함수 정의하기
def train(train_loader, model, criterion, optimizer, device):
'''
training loop의 training 단계에 대한 함수
'''
model.train()
running_loss = 0
for X, y_true in train_loader:
optimizer.zero_grad()
X = X.to(device)
y_true = y_true.to(device)
# 순전파
y_hat, _ = model(X)
loss = criterion(y_hat, y_true)
running_loss += loss.item() * X.size(0)
# 역전파
loss.backward()
optimizer.step()
epoch_loss = running_loss / len(train_loader.dataset)
return model, optimizer, epoch_lossoptimizer.zero_grad() / model.zero_grad() : pytorch에서는 loss.backward()를 호출할 때 gradients 값을 계속 더해주기 때문에 한번 학습이 완료되면 graidents를 0으로 만들어야 함
training에서는 순전파, 역전파 모두 사용
(6) validation data에 사용되는 함수 정의하기
def validate(valid_loader, model, criterion, device):
'''
training loop의 validation 단계에 대한 함수
'''
model.eval()
running_loss = 0
for X, y_true in valid_loader:
X = X.to(device)
y_true = y_true.to(device)
# 순전파와 손실 기록하기
y_hat, _ = model(X)
loss = criterion(y_hat, y_true)
running_loss += loss.item() * X.size(0)
epoch_loss = running_loss / len(valid_loader.dataset)
return model, epoch_lossvalidation에서는 역전파 사용하지 않음
(7) training loop 정의하기
def training_loop(model, criterion, optimizer, train_loader, valid_loader, epochs, device, print_every=1):
'''
전체 training loop를 정의하는 함수
'''
# metrics를 저장하기 위한 객체 설정
best_loss = 1e10
train_losses = []
valid_losses = []
# model 학습하기
for epoch in range(0, epochs):
# training
model, optimizer, train_loss = train(train_loader, model, criterion, optimizer, device)
train_losses.append(train_loss)
# validation
with torch.no_grad():
model, valid_loss = validate(valid_loader, model, criterion, device)
valid_losses.append(valid_loss)
if epoch % print_every == (print_every - 1):
train_acc = get_accuracy(model, train_loader, device=device)
valid_acc = get_accuracy(model, valid_loader, device=device)
print(f'{datetime.now().time().replace(microsecond=0)} --- '
f'Epoch: {epoch}\t'
f'Train loss: {train_loss:.4f}\t'
f'Valid loss: {valid_loss:.4f}\t'
f'Train accuracy: {100 * train_acc:.2f}\t'
f'Valid accuracy: {100 * valid_acc:.2f}')
plot_losses(train_losses, valid_losses)
return model, optimizer, (train_losses, valid_losses)training, validation의 loss, accuracy를 기록하는 함수
(8) data 준비하기
# transforms 정의하기
transforms = transforms.Compose([transforms.Resize((32, 32)),
transforms.ToTensor()])
# data set 다운받고 생성하기
train_dataset = datasets.MNIST(root='mnist_data',
train=True,
transform=transforms,
download=True)
valid_dataset = datasets.MNIST(root='mnist_data',
train=False,
transform=transforms)
# data loader 정의하기
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=BATCH_SIZE,
shuffle=False)data는 torchvision에서 제공하는 MNIST data를 사용한다.
(8-1) 불러온 MNIST data 확인
ROW_IMG = 10
N_ROWS = 5
fig = plt.figure()
for index in range(1, ROW_IMG * N_ROWS + 1):
plt.subplot(N_ROWS, ROW_IMG, index)
plt.axis('off')
plt.imshow(train_dataset.data[index], cmap='gray_r')
fig.suptitle('MNIST Dataset - preview');
(9) LeNet-5 구조 정의하기
맨 위에서 정리했던 구조
- Input Layer : 32x32
- C1 (Convolution) : 28x28x6
- S2 (Subsampling) : 14x14x6
- C3 (Convolution) : 10x10x16
- S4 (Subsampling) : 5x5x16
- C5 (Fully connection) : Layer 120 => classifier
- F6 (Fully Connection) : Layer 84 => classifier
- Output (Gaussian connections) : 10
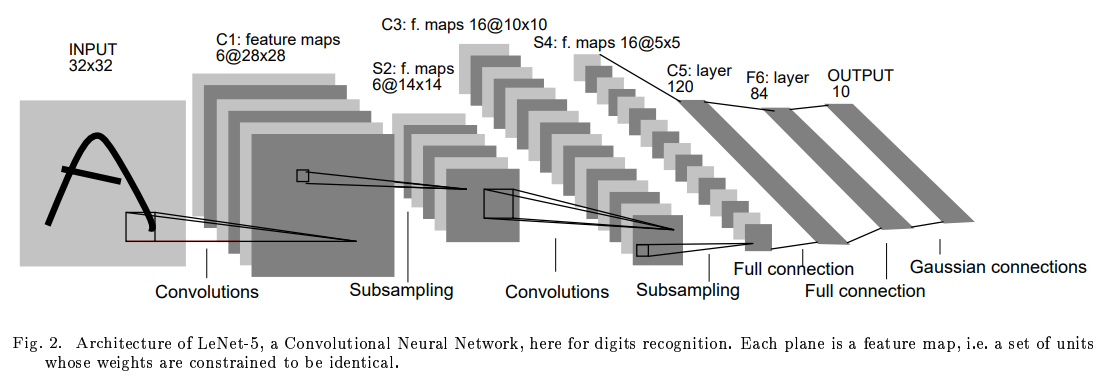
Input-> C1, S2-> C3, S3->C5 일 때 kenel_size=5인 필터가 특징을 추출함 => feature map 사이즈가 가로세로 4씩 작아짐
C1->S2, C3->S4일 때 AveragePooling으로 평균값을 취합함 => feature map 사이즈가 가로세로 모두 1/2됨
class LeNet5(nn.Module):
def __init__(self, n_classes):
super(LeNet5, self).__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2),
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2),
nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5, stride=1),
nn.Tanh()
)
self.classifier = nn.Sequential(
nn.Linear(in_features=120, out_features=84),
nn.Tanh(),
nn.Linear(in_features=84, out_features=n_classes),
)
def forward(self, x):
x = self.feature_extractor(x)
x = torch.flatten(x, 1)
logits = self.classifier(x)
probs = F.softmax(logits, dim=1)
return logits, probs(10) model, optimizer, loss function 설정하기
torch.manual_seed(RANDOM_SEED)
model = LeNet5(N_CLASSES).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
criterion = nn.CrossEntropyLoss()torch.manual_seed : random_seed를 고정하기 위한 함수
(11) 신경망 학습하기
model, optimizer, _ = training_loop(model, criterion, optimizer, train_loader,
valid_loader, N_EPOCHS, DEVICE)
(12) 결과
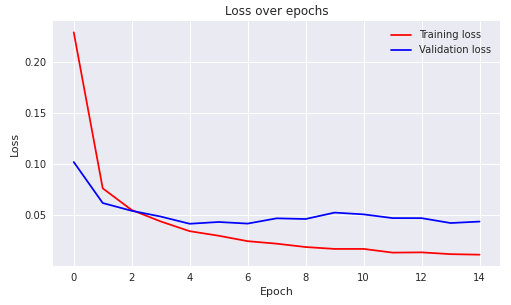
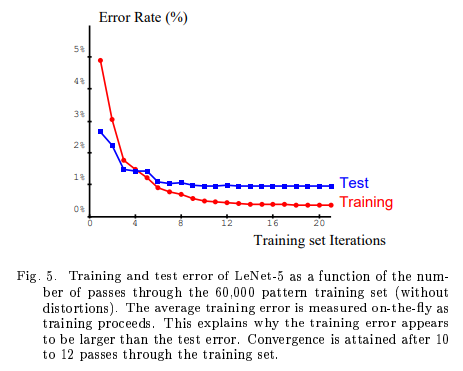
논문에서 10~15 epoch 쯤에 수렴한다고 나와있어서 작성자님도 15 epoch으로 설정한 것 같다.
그래프의 양상도 유사함 !
다 하고 보니 Pytorch 한국어 번역 사이트에도 잘 나와있다.
같은 torch 방식이더라도 이런 식으로 할 수도 있구나 싶었음
근데 아래의 방법은 tanh 대신 relu, average-pooling 대신 max-pooling을 사용했다.
위의 코드가 각 레이어가 코드로 쌓인 느낌도 나고 feature extractor랑 classifier가 구분되어 있어서 Lenet-5 그림이 직관적으로 잘 그려지는 것 같음
하지만 코드 자체는 아래의 코드가 더 깔끔하고 보기 좋다. 정갈해...
그리고 레이어 부분이랑 중간 처리되는 부분 (pooling, relu 등)의 부분이 구분되어 있어서 이것도 나름 좋은 듯
신경망 정의하기
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)https://9bow.github.io/PyTorch-tutorials-kr-0.3.1/beginner/blitz/neural_networks_tutorial.html
신경망(Neural Networks) — PyTorch Tutorials 0.3.1 documentation
신경망은 torch.nn 패키지를 사용하여 생성할 수 있습니다. 지금까지 autograd 를 살펴봤는데요, nn 은 모델을 정의하고 미분하는데 autograd 를 사용합니다. nn.Module 은 계층(layer)과 output 을 반환하는 for
9bow.github.io
Reference
[1] http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
[2] https://deep-learning-study.tistory.com/368
[3] http://www.terms.co.kr/mount.htm
[4] https://yuevelyne.tistory.com/10
[5] https://algopoolja.tistory.com/55
[6] https://9bow.github.io/PyTorch-tutorials-kr-0.3.1/beginner/blitz/neural_networks_tutorial.html



