
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- long video understanding
- 백준
- MySQL
- hackerrank
- timestamp-aware frame encoder
- q-former
- sliding video q-former
- error
- ma-lmm
- CNN
- LeNet-5
- tensorflow
- secure-file-priv
- leetcode
- 용어
- memory bank
- transference
- quantification
- jmeter
- autogluon
- Python
- Kaggle
- 코딩테스트
- Github
- Linux
- Anaconda
- multimodal machine learning
- Artificial Intelligence
- timechat
- Server
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- long video understanding
- 백준
- MySQL
- hackerrank
- timestamp-aware frame encoder
- q-former
- sliding video q-former
- error
- ma-lmm
- CNN
- LeNet-5
- tensorflow
- secure-file-priv
- leetcode
- 용어
- memory bank
- transference
- quantification
- jmeter
- autogluon
- Python
- Kaggle
- 코딩테스트
- Github
- Linux
- Anaconda
- multimodal machine learning
- Artificial Intelligence
- timechat
- Server
- Today
- Total
목록전체 글 (54)
Juni_DEV
멀티모달 러닝은 다양한 형태의 데이터(예: 텍스트, 이미지, 음성 등)를 통합하여 컴퓨터가 이를 이해하고, 추론하고, 학습할 수 있도록 돕는 인공지능 기술입니다. 멀티모달 러닝의 목표는 다양한 데이터를 연계하여 통합적으로 처리할 수 있는 지능형 컴퓨터 에이전트를 설계하는 것입니다. 여기에서는 멀티모달 러닝의 핵심 원칙과 대표적인 기술적 과제들을 정리해보겠습니다.멀티모달 러닝의 핵심 원칙멀티모달 러닝의 기본 원칙은 크게 다음 세 가지로 요약할 수 있습니다.모달리티의 이질성: 서로 다른 데이터 유형(텍스트, 이미지, 소리 등)은 고유한 특성과 구조를 가지며, 이를 잘 반영해야만 최적의 결과를 얻을 수 있습니다.모달리티 간의 연결: 각 모달리티 간의 연관성을 파악하고 연결함으로써 서로 보완적인 정보를 통합합니..
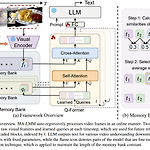 [논문리뷰] MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
[논문리뷰] MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
https://arxiv.org/abs/2404.05726이 논문에서는 MA-LMM(Memory-Augmented Large Multimodal Model)을 제안하여 Long-Term Video Understanding를 위한 새로운 접근법을 제시하고 있습니다. 기존의 LLM 기반 모델들이 짧은 비디오 이해에만 적합한 반면, MA-LMM은 장기 비디오 시퀀스를 온라인으로 처리하고, 이전 비디오 정보를 메모리 뱅크에 저장하여 효율적으로 분석합니다. 이로 인해 LLM의 컨텍스트 길이 제한이나 GPU 메모리 한계를 초과하지 않고도 긴 비디오를 다룰 수 있습니다.MA-LMM ArchitectureMA-LMM의 기본 구조는 크게 세 부분으로 나눌 수 있습니다.Visual Encoder: 입력된 비디오의 각 프레..
 Classification Metrics: Precision, Recall, F1 Score, Accuracy
Classification Metrics: Precision, Recall, F1 Score, Accuracy
F1 Score, Precision, Recall, Accuracy는 분류(classification)에서 모델의 성능을 평가하기 위해 사용되는 지표들입니다. 이들 각각은 모델이 얼마나 잘 작동하는지에 대한 다양한 측면을 측정합니다.Precision (정밀도)정의: 모델이 Positive로 예측한 것들 중 실제로 Positive인 것의 비율을 나타냅니다.수식: Precision = TP / TP + FP - TP: True Positive (실제로 Positive인 것을 Positive로 예측한 경우)- FP: False Positive (실제로는 Negative인 것을 Positive로 잘못 예측한 경우)설명: Precision는 모델이 얼마나 정확하게 Positive 클래스를 예측하는지 측정하며, 잘..
 [논문리뷰] TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding
[논문리뷰] TimeChat: A Time-sensitive Multimodal Large Language Model for Long Video Understanding
https://arxiv.org/abs/2312.02051이 논문은 긴 비디오 이해를 위해 특별히 설계된 TimeChat이라는 시간 민감형 다중모달 대형 언어 모델을 제안합니다. TimeChat은 두 가지 핵심 기능을 갖추고 있습니다. 첫째, Timestamp-aware frame encoder로 각 비디오 프레임의 시각적 콘텐츠와 타임스탬프를 결합합니다. 둘째, Sliding video Q-Former를 통해 다양한 길이의 비디오를 처리할 수 있도록 비디오 토큰 시퀀스를 생성합니다.또한, TimeChat의 명령 수행 능력을 향상시키기 위해 6개의 주요 비디오 작업을 다루는 12만 5천 개의 인스턴스를 포함한 명령 튜닝 데이터셋(TimeIT)을 구축했습니다.실험 결과, TimeChat은 제로샷 시간적 위..
Kaggle Featured 대회인 ISIC 2024 - Skin Cancer Detection with 3D-TBP에 참여하면서, 다양한 피처를 분석하고 각 피처의 의미 있는지 여부를 확인하는 과정을 거쳤습니다. 이 과정에서, 모델 학습 시 어떤 피처들이 예측에 중요한 영향을 미치는지 확인하며 관련 기법들을 공부하게 되었습니다. Forward Selection, Backward Elimination, Stepwise, Genetic Algorithm, 상관관계 분석, Feature Importance 확인, SHAP 등 총 7가지 기법을 적용해 분석을 시도했습니다.1. Forward Selection (전방 선택)Forward Selection은 피처를 하나씩 추가하면서 모델 성능을 개선하는 방식의 피..
 [Kaggle] Playground Season4, Episode 8 - Binary Prediction of Poisonous Mushrooms
[Kaggle] Playground Season4, Episode 8 - Binary Prediction of Poisonous Mushrooms
오늘부로 Kaggle Playground Series - Season 4, Episode 8 독버섯 예측 대회가 마무리되었습니다. Binary Prediction of Poisonous Mushrooms | Kaggle www.kaggle.com이 대회의 목표는 버섯의 물리적 특성을 바탕으로 해당 버섯이 식용 가능한지 아니면 독성이 있는지를 예측하는 것입니다.이 대회에서 제공된 데이터셋(훈련 및 테스트용)은 UCI Mushroom 데이터셋을 기반으로 훈련된 딥러닝 모델에서 생성되었고, 특징 분포는 원본과 유사하지만 정확히 동일하지는 않습니다. 원본 데이터셋을 사용하여 차이점을 탐구하거나, 원본 데이터를 훈련에 포함시켜 모델 성능을 향상할 수 있는지 확인해 볼 수 있습니다.그리고 아래 세 파일을 제공합니다..
이 오류는 일반적으로 NumPy 버전과 SciPy 버전 간의 호환성 문제로 인해 발생합니다. 특히, NumPy와 SciPy가 서로 다른 버전으로 설치되어 있을 때 발생할 수 있습니다. 1. NumPy와 SciPy 버전 확인현재 설치된 NumPy와 SciPy의 버전을 확인합니다.import numpy as npimport scipyprint("NumPy version:", np.__version__)print("SciPy version:", scipy.__version__)2. 호환 가능한 버전으로 업데이트터미널에서 다음 명령어를 사용하여 최신 버전으로 업데이트합니다.pip install --upgrade numpy scipy3. 버전 호환성 유지특정 패키지 버전 간의 호환성 문제가 발생할 수 있으므로, ..
AutoGluon은 Amazon Web Services(AWS)에서 개발한 오픈 소스 자동화 머신러닝(AutoML) 라이브러리입니다. 이번에 Kaggle Playground 대회를 준비하며 처음 접하게 되었는데, 이 라이브러리를 통해 적은 노력으로 강력한 머신러닝 모델을 구축할 수 있었고, 알아서 제공된 데이터에 대해 자동화된 최적 모델을 제공해줘서 정말 유용했습니다. 이번 글에서는 AutoGluon을 사용하는 방법을 알아보겠습니다.1. AutoGluon 설치하기pip install autogluon 2. 데이터 준비하기AutoGluon은 다양한 데이터 형식을 지원하지만, 일반적으로 CSV 파일을 사용해 데이터를 로드합니다.import pandas as pd# 데이터 로드train_data = pd.r..